MongoDB启动报错WARNING: You are running on a NUMA machine.
MongoDB启动报错WARNING: You are running on a NUMA machine.
今天,MongoDB服务器突然非常的卡,直接要宕机的节奏。哎,又要用到最快的解决问题的方法——重启。
但是服务器重启非常的慢。按理说超过2T的硬盘容量(我们的是8T),重启速度确实会比2T以内时间时间久,大约是2T容量的3倍,大约3-4m。汗,我们服务器都重启20m了,肯定有问题。
想想,这个台服务器只装了MongDB,其他都没安装。果断找Mongo日志。一翻日志,出来问题了。
存在问题:
在用 /usr/local/mongodb/bin/mongod –dbpath=/usr/local/mongodb/data –logpath=/usr/local/mongodb/logs –logappend –port=27017 启动MongoDB的时候报了如下错误
WARNING: You are running on a NUMA machine. 具体如图所示:

此时如果查看irqbalance这个进程,会发现占用cpu居高不下。
既然找到问题了,就好办了。
解决方案:
其实,日志中已经给予解答了——改用 numactl –interleave=all mongod [othor options]
运行如下代码,
numactl –interleave=all /usr/local/mongodb/bin/mongod –dbpath=/usr/local/mongodb/data –logpath=/usr/local/mongodb/logs –logappend –port=27017
再次查看日志,该警告不复存在,问题解决。
问题小结:
NUMA做简要介绍:
NUMA是多核心CPU架构中的一种,其全称为Non-Uniform MemoryAccess,简单来说就是在多核心CPU中,机器的物理内存是分配给各个核的。结构图如下:
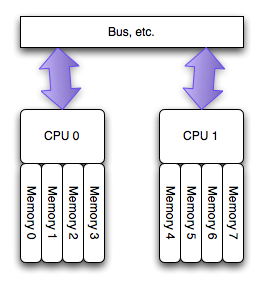
简单做下解释,NUMA架构中每个核访问分配给自己的内存,会比分配给其他核内存要快,有下面几种访问控制策略:
- 缺省(default):总是在本地节点分配(分配在当前进程运行的节点上);
- 绑定(bind):强制分配到指定节点上;
- 交叉(interleave):在所有节点或者指定的节点上交织分配;
- 优先(preferred):在指定节点上分配,失败则在其他节点上分配。
但是目前mongodb在这种架构下工作的不是很好,–interleave=all就是禁用NUMA为每个核单独分配内存的机制,改用交叉共享内存分配模式
irqbalance:
irqbalance上面提到的一个占用CPU的进程,这个进程的作用是在多核心CPU的操作系统中,分配系统中断信号的。参见:irqbalance.org
概念说完了,下面是上面问题的简单描述:
我们知道虚拟内存机制是通过一个中断信号来通知虚拟内存系统进行内存swap的,所以这个irqbalance进程忙,是一个危险信号,在这里是由于在进行频繁的内存交换。
这种频繁交换现象称为swap insanity,在MySQL中经常提到,也就是在NUMA框架中,采用不合适的策略,导致核心只能从指定内存块节点上分配内存,
即使总内存还有富余,也会由于当前节点内存不足时产生大量的swap操作。
对于NUMA,进一步了解可以参考:NUMA与英特尔下一代Xeon处理器 和 MySQL单机多实例方案 两篇文章
通过上图可以看到还报另外一个警告:WARNING: You are running on a NUMA machine. 这篇文章有相关的介绍 http://www.uuboku.com/302.html
MongoDB启动报错WARNING: You are running on a NUMA machine.
相关推荐
- php解析html 中的php
- Posted on 05月09日
- LNMP(linux+nginx+mysql+php)服务器环境配置
- Posted on 12月14日
- mongoDB常用操作命令 终端常用操作命令
- Posted on 07月15日
- linux查看cpu个数、核心数、进程数、内存大小、硬盘大小、网卡信息等信息
- Posted on 05月29日